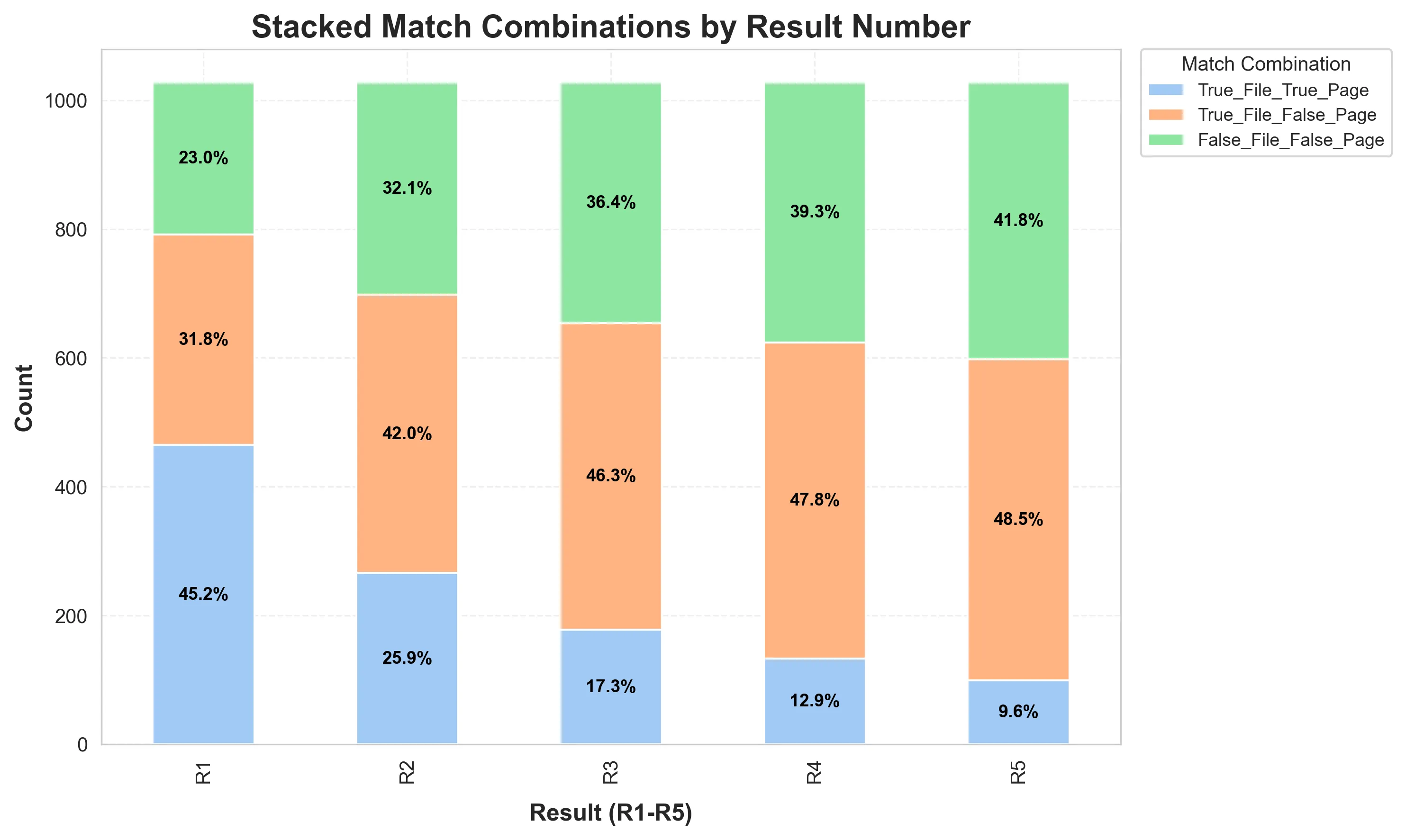
RAG
This is a modular RAG pipeline!
Built to compare different parts of the RAG pipeline.
It is easy to customize and extend.
Uses ChromaDB as vector database.
Can be used to compare:
Parsers
Chunking Strategies
Embedding Models
Re-Reankers
Context Adding Strategies
It allows users to load embedding models in three ways:
API calls
Local Server
Transformers
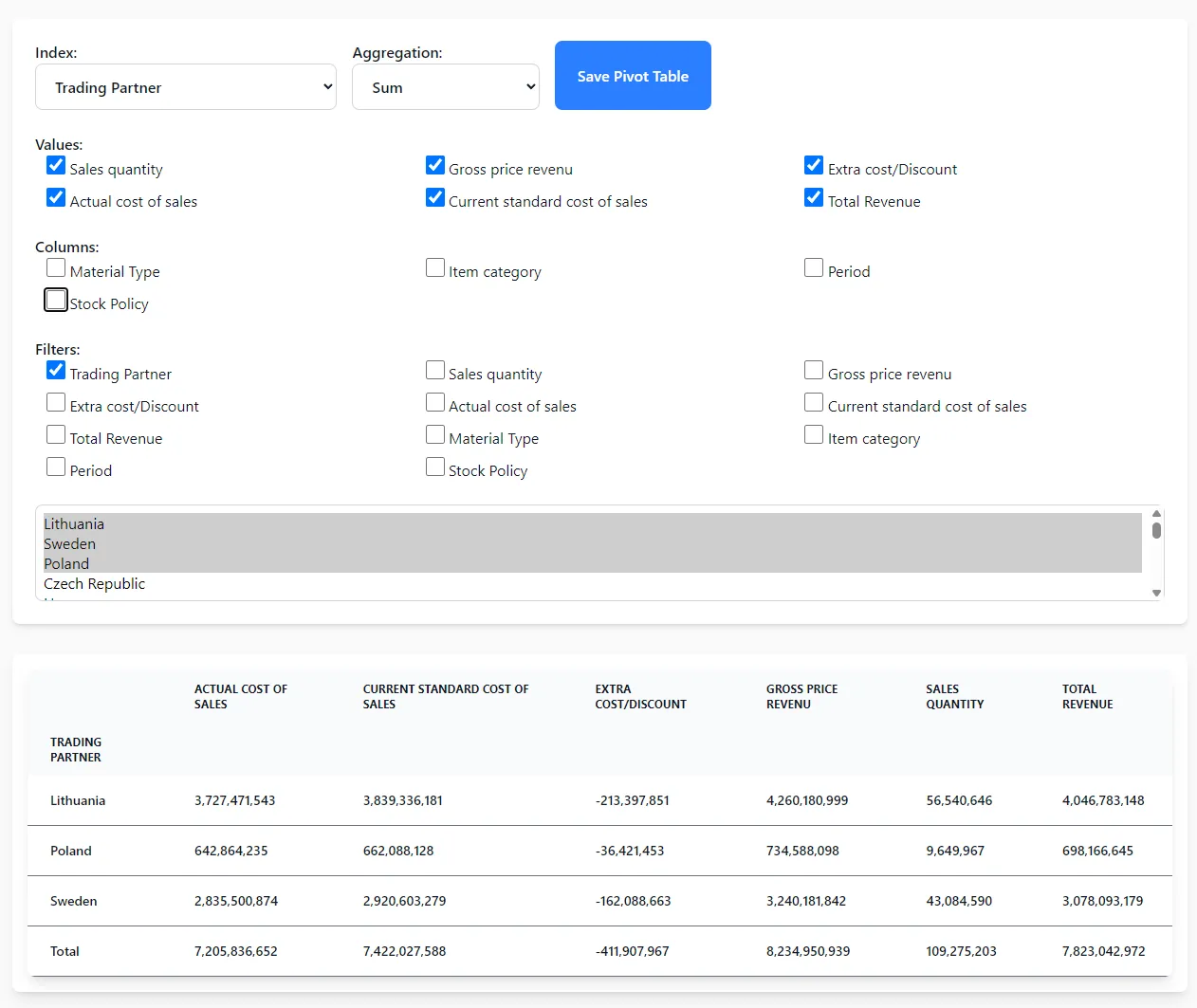
There are helping scripts to increase efficiency during tesing.
You can find scripts for: Pre-rendering files as markdown files,
Calculating accuracy, getting csv files with results,
generating plots, generating LLM responses, and some other usfull stuff.
Have a look around the repository!